Con este contenido damos por terminado la saga de OpnSense+Web Proxy Transparente+Plugin OpnProxy, si han implementado Squid en OpnSense siguiendo los 2 videos anteriores, entonces ya tiene muchos logs y solo nos falta la cereza del pastel, como obtener los reportes de navegación.
OpnSense no cuenta con una herramienta en sus Plugins para llevar a cabo esto, tenemos que hacer uso de las paqueterias de FreeBSD, el padre de OpnSense, pero debo aclarar que el equipo de OpnSense no se hara responsable si algo no funciona, porque estamos usando software de 3ros.
Entonces cuando llevemos a cabo las actualizaciones de OpnSense no se les olvide revisar que esta aplicacion siga funcionando.
SARG Squid Analysis Report Generator
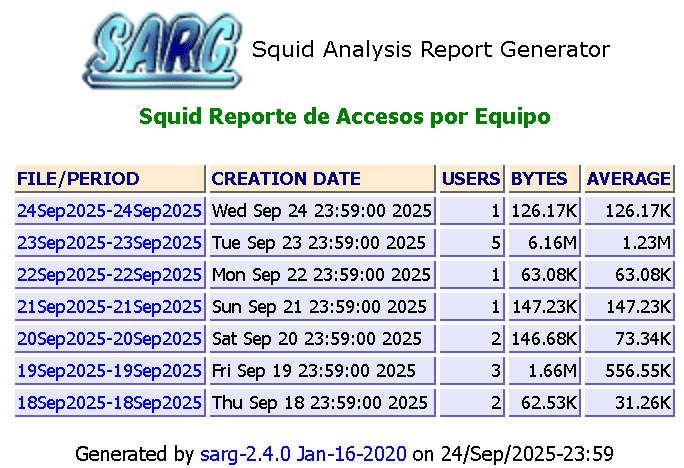
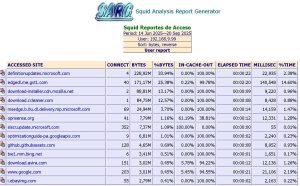
Sarg es la herramienta encargada de obtener los reportes como los que muestro en la siguiente imagen:
Reportes de Squid
Puede observar que por cada dia se cuenta con un reporte y si seleccionamos cualquiera de las fechas, obtenemos algo similar a lo anterior, los usuarios que nevagaron.
No se desesperen, ya llegaremos a esto.
Existen otras herramientas como LightSquid la cual utiliza Pfsense, pero en lo personal, SARG siempre me ha parecido superior, pero como siempre he dicho, el gusto se rompe en generos.
Como lo comente anteriormente, tienen que tener trabajando a Squid en OpnSense para que genere logs, que nos registre cada uno de los destinos web que nuestros usuarios acceden y con esto Sarg se encargara del resto.
Posiblemente se preguntaran, ¿De donde obtiene SARG esos reportes?, muy sencillo, de el log de Squid:
access.log
Que se localiza en:
/var/log/squid
No se les olvide esto cuando editen el archivo de configuracion de SARG.
Video #1
Todo inicia desde el 1er video donde hablamos sobre squid y como configurarlo, asi que si aun no lo han llevado a cabo, aqui se los dejo, si ya lo tienen trabajando, saltense hasta el tema de configuracion de SARG.
Una vez puesto en marcha, empieza el log de squid a registrar los destinos de los usuarios, que es de donde sarg obtiene los reportes.
Video #2
Y una vez terminado y puesto en marcha el video anterior, continuan con este 2do video, donde llevamos a cabo los famosos ACL o controles de acceso a Internet con los que cuenta Squid, esto se lleva usando su plugin llamado OpnProxy, es el video mas largo de la saga pero el que realmente nos permite controlar a cada uno de nuestros usuarios, aqui se los dejo.
Ahora, una vez finalizado este 2do video, ademas de los sitios permitidos, tambien empezara squid a registrar los sitios no permitidos, y con esto ceramos el circulo, todo esto lo vamos a poder observar cuando sarg obtenga los reportes.
Instalacion de SARG
Para instalar sarg requerimos acceso a la consola, o sea atraves de ssh a OpnSense y solo ejecutamos este comando
root@fwproxy:/var/log/squid # pkg install sarg
Y solo esperamos descargue todo lo necesario y lo mas importante, que no marque error. Les recuerdo, este paquete no viene en la paqueteria oficial de OpnSense, aqui estamos usando los paquetes de su OS padre FreeBSD.
Configuración de SARG
Por utilizar FreeBSD como su OS padre, OpnSense sigue sus lineamientos, por lo tanto la configuracion de SARG se localiza en esta ruta:
/usr/local/etc/sarg
Y dentro de su directorio se encuentran varios archivos, aqui se los muestro:
Archivos de Sarg
El archivo de configuracion de sarg debe llamarse sarg.conf, por lo tanto vamos a generarlo atraves de la plantilla base, la que tiene nombre de sarg.conf.sample. De una manera muy simple:
Primero nos movemos a la ubicacion de la configuracion:
cd /usr/local/etc/sarg
y creamos una copia de la plantilla base, asi:
cp sarg.conf.sample sarg.conf
Listo, ahora si pasamos a configurar sarg.
sarg.conf
Les recuerdo que el editor base de OpnSense es ‘ee‘, es mas sencillo que vi, y no trae nano de fabrica. Asi que abrimos nuestro archivo y lo vamos a dejar de la siguiente manera:
NOTA: Es muy extensa la configuracion de sarg, no se asusten.
# sarg.conf
#
# TAG: access_log file
# Where is the access.log file
#
# This option can be repeated multiple times to list rotated files or
# files from different sources.
#
# The files named here must exists or sarg aborts. It is intended as a
# safety against incomplete reporting due to problems occuring with the
# logs.
#
# If the file globbing was compiled in, the file name can contain shell
# wildcards such as * and ?. Tilde expension and variable expension are
# not supported. Special characters can be escaped with a backslash.
#
# If some files are passed on the command line with “sarg -l file” or
Si revisan el archivo, hay un parametro que dice asi:
output_dir /usr/local/www/squid-reports
Ese directorio es donde sarg almacenara todos los reportes dia con dia, como no existe lo tenemos que crear. Asi que nos regresamos a la consola y ejecutamos el siguiente comando:
mkdir /usr/local/www/squid-reports
Listo.
Prueba Manual de Sarg
Vamos hacer nuestro check-list:
1)Sarg ya esta instalado
2)Archivo de configuracion listo(sarg.conf)
3)Directorio de almacenamiento de reportes creado.
4)Ya tenemos registros en el log de squid, access.log
Entonces ejecutamos desde la consola, asi:
/usr/local/bin/sarg
Dependiendo el tamaño del archivo puede durar unos minutos o bien, al instante, es muy eficiente sarg. Ahora para validarlo, en nuestro navegador apunten a el ip o hostname de OpnSense a el directorio de los reportes de squid:
https://ip-opnsense/squid-reports
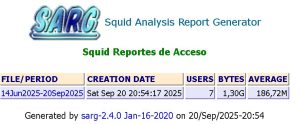
Squid Reports
Observen que en mi caso se ha consumido 1.3GB de datos de navegacion. Ahora, vemos los detalles, le damos un click a la fecha y veremos algo similar a la siguiente imagen:
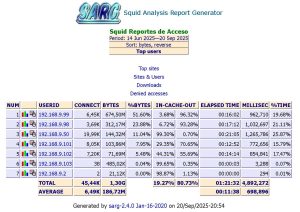
Detalles del Reporte
Sin miedo en la parte alta tenemos varios reportes, a la izquierda los clientes que navegaron atraves de este proxy, pongan atencion y observaran la columna ‘bytes‘, esa nos indica cuanto consumo este usuario de datos de navegacion, informacion muy valiosa.
Ahora le dare un click a uno de mis usuarios para ver los destinos que accedio y cuantos datos consumio en cada destino, de igual manera ponganle atencion a los sitios bloqueados ‘DENIED’.
Reporte de Usuario
Ustedes mismos revisen el resto de los reportes y analicen la informacion mostrada.
Agregar Sarg a Cron
Ya validamos que sarg esta funcionando, ahora lo que sigue es que atraves de cron se ejecute para que todos los dias antes de la media noche obtenga el reporte del dia, ya que a la media noche, squid rota su log(access.log). No podemos usar los mecanismos clasicos de Unix(OpnSense es un Unix) para hacer esto, ocupamos usar los mecanismos de OpnSense.
Para esto, vamos a crear un arhivo de nombre ‘actions_sarg.conf” en esta ruta:
/usr/local/opnsense/service/conf/actions.d
A el archivo le agregamos este contenido:
[restart] command:/usr/local/bin/sarg parameters: type:script message: description:Reportes de Squid
Salvamos y salimos.
Lo que sigue es reiniciar el servicio: configd, para estos nos vamos a System->Diagnostics->Services
Buscamos el servicio configdy lo reiniciamos.
Reiniciar configd
Ahora nos regresamos a el GUI de OpnSense, a el menu: System->Settings->Cron.
Presionamos el icono de + que se localiza a la derecha, ver siguiente imagen:
Agregamos Nueva Tarea
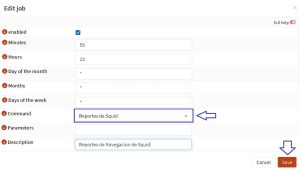
Y configuramos a sarg para que se ejecute todos los dias a las 23:59, antes que squid rote su archivo, ver siguiente imagen.
Agregar Reporte de Sarg
Si todo funciona, tendremos ya 2 reportes con la misma fecha, ya que recuerden, lo ejecutamos de manera manual, si desean borar los reportes creados hasta hoy, borren el contenido del directorio de reportes y listo.
cd /usr/local/www/squid-reports
rm -rf ./*
De igual manera, les recomiendo limpiar el cache de sus navegador, por que les puede mentir y aunque hayan borrado el contenido del directorio, les puede mostrar el reporte de su cache.
Ya solo esperar se ejecuten via cron, si no funciona, les recomiendo regresar al inicio y empezar de nuevo.
Resumen
Ahora si podemos dar por terminada la saga de OpnSense y su WebProxy en ModoTransparente con su PluginOpnProxy para los controles de acceso(ACL) de squid. Hay mucho discusion sobre si hoy en dia, aun es conveniente implementar squid para controlar el acceso a Internet. Cuando llegan a OpnSense, una de las preguntas basicas es, ¿Como puedo ver a que paginas mis usuarios nevegan?, de fabrica OpnSense es un firewall, el solo esta filtrando paquetes a nivel IP+puerto.
Aunque el tiene manera de saber a que destinos los usuarios acceden, no es una tarea de un firewall como tal, su funcion es permitir o no el destino+puerto del cliente, un firewall no lidia con, es facebook.com este no, es playboy.com este tampoco, es yahoo.com.mx este si. Y pueden decirme, oyes pero si agrego un alias y ahi coloco los destinos anteriores que no deseo mis usuario accesen, entonces si sabe sobre ellos.
Si, pero el no tiene un reporte para entregarles que destino bloqueo, y no hay un reporte como tal de fabrica.
Por ello, la unica manera de respoder la pregunta es, implementando un web proxy, aun que a veces es tedioso lo se, pero es la unica manera de obtener esos datos.
Notaran que sarg nos ofrece informacion muy valiosa, como cuanto consume cada usuario dia con dia, a que destinos van, a que horas, otro dato muy interesante, a que destinos prohibidos intentan acceder, en mi tiempo como sys admin, ya hemos dado de baja empleados de rango gerentes de departamento gracias a squid+sarg.
Ahora, por el otro lado, muchos sys admins prefieren no lidiar con un web proxy y prefieren usar herramientas en los equipos de los usuario finales, ya sea con el mismo AV, es tambien valido, no existe un unico camino en como controlar el acceso a Internet.
Lo mas importante es la valiosa informacion que nos brinda sarg para toma de decisiones y poner en cinta a los usuarios, es mas importante que el departamento de nomina pueda llevar a cabo el pago de los empleados, que compras pueda comprar la materia prima o que ventas amarre un nuevo pedido, que un empleado este agusto viendo un capitulo de su programa favorito, como les he preguntado varias veces, ¿que prefieren, que llores en tu casa o que lloren en la casa del otro?